Advanced RAG for a Complex Schema
Previously, we had developed a simple chatbot by creating an Information Tool. This Information Tool would dynamically generate a Cypher Query and fetch information from the Neo4j Database.
We are using a technique called Retrieval-Augmented Generation (RAG) to enhance responses by integrating data from Neo4j. The chatbot utilizes LangChain to manage language models and workflow orchestration.
We hit a roadblock in terms of cost and performance as our schema became more complex. In order to overcome this challenge, we've made significant changes to our approach. Now, we are using two tools instead of one Information Tool to retrieve the data. We will discuss these changes in more detail in the below post.
Why the Split? Understanding the Need for Two Tools
The Challenge with a Single Tool
Our initial approach relied on a single information tool for all database interactions. However, as our schema grew more complex, this method became inefficient and expensive due to increased token usage. We needed a more structured and efficient way to query entity data and relationships.
The Interaction #2 (between the Agent & the LLM) in the below diagram saw increased token usage due to the schema becoming more complex.
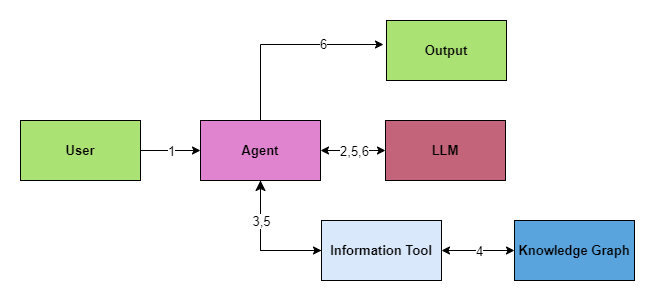
- User (Query) → Agent
- Agent (send: prompt, query, enhanced context and schema ) ←→ LLM (Infers input to the Information Tool)
- Agent → Information Tool
- Information Tool (Cypher Query) ←→ Knowledge Graph (Result)
- Information Tool (Result) → Agent → LLM (Process the Result of the Cypher Query)
- LLM → Agent → Output (Final Output)
Solution: Splitting the Tool
We split the information tool into two distinct parts: Entity Tool and Entity Data Tool.
We pass a limited (but relavant schema) in Interaction #5.
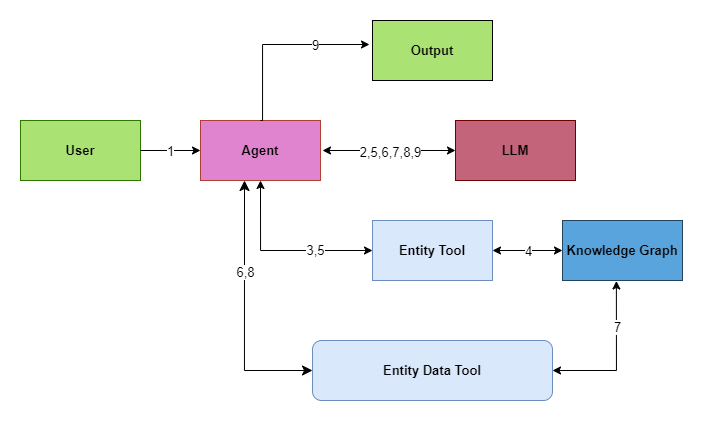
- User (Query) → Agent
- Agent (prompt, query, and enhanced context) ←→ LLM (responds back with ONLY the possible Entity)
- Agent (Possible Entity) → Entity Tool
- Entity Tool (Cypher Query to get the Entity Type) ←→ Knowledge Graph (Returns Entity Type and only the
relavant schemarelated to the Entity Type in a Structured Output) - Entity Tool (Structured Output) → Agent → LLM (Process the Structured Output)
- LLM (Generates a Structured Input Based on the Structured Output generated by the Entity Tool) → Agent → Entity Data Tool (Structured Input)
- Entity Data Tool (Generate New Cypher Query) ←→ Knowledge Graph (Returns Entity Details in Structured Format)
- Entity Data Tool (Output of the previous step) → Agent → LLM (Reword the Structured Format into Natural Language)
- LLM → Agent → Output (Final output)
By splitting the tool into Entity Tool and Entity Data Tool, we achieved:
- Improved Efficiency: Each tool specializes in its function, making queries faster and more accurate.
- Scalability: The tools handle more complex and dynamic schemas more effectively.
- Cost Management: More efficient data handling reduces costs.
The Entity Tool: Finding and Understanding the Entity
What is an Entity?
An Entity can be almost anything. For example: System, Process, Script, Person, Cat, Dog etc.
What is the Entity Tool?
The Entity Tool is designed to help you locate and understand information about entities and its related schema within our Neo4j database. The tool simplifies querying and managing entity information, enhancing the accuracy and efficiency of your searches.
How Does It Work?
- Input: The user submits a question to the chatbot, which subsequently transmits it to the LLM (Large Language Model) to identify the relevant entity from the question.
- Dynamic Query Creation: The tool generates a query to search for this entity in the database using the indexed data.
- Executing the Query: The tool runs the query and verifies the results:
- No Results: It notifies you if nothing has been found.
- Multiple Results: It further requests you to provide a few more details to narrow down the search.
- One Result: It delivers information about the entity and its related schema.
- Returning Results: It delivers details like the entity’s name, entity type, property name, and related information.
Why is it Useful?
The Entity Tool streamlines finding entity-related information such as an entity’s name, entity type, and property name. It also ensures accuracy and improves user experience by refining searches when multiple results appear.
The Entity Data Tool: Exploring Relationships
What is the Entity Data Tool?
The Entity Data Tool focuses on querying detailed relationship data about entities. It handles various criteria such as relationship types, entity types, and directions to generate and execute queries, offering insights into how entities are interconnected.
How Does It Work?
- Input Details: The details, such as the entity name, entity type, properties, and relationship information, from the
Entity Tool, are processed by the LLM and then result of that processing is fed into the Entity Data Tool. - Creating the Query: We wrote a Cypher query generator that utilizes variables such as the source node, destination node, direction, relationship type, and owner type, and generates a Cypher Query all tailored to the user's question.
- Executing the Query: It runs the query and returns the results accordingly.
The Current Structure and Its Benefits
Current Structure
- Entity Tool: Always invoked first, it identifies and provides basic information about entities.
- Entity Data Tool: Invoked after the EntityTool, it explores detailed relationships and properties of the identified entities.
We are using pydantic output format to store the output in a structured manner.
Benefits Over the Old Structure
- Specialization: Each tool has a clear, specific purpose.
- Efficiency: Faster query execution and better data management.
- Scalability: Handles growing data volumes without performance degradation.
- Cost-Effective: Reduces data handling costs.
Learning and Challenges
LLMs Hallucinating
- Fixed by setting the temperature to zero.
Rapid Pace of Change on the LLM Provider Side
- Code encounters errors due to modifications in the APIs.
- Solution: Pin your libraries to avoid breaking changes.
Challenges in Scaling
- With data scaling up, things break!
- Also, with data increase, costs exponentially increase!
- Solution: Chains -> Break your problem into small steps. No need to overwhelm the LLM with all your data at once.
Ask the LLMs to Give You a Structured Output
- If you are using intermediate steps, ask the LLM to give you a structured output like JSON, Pydantic, CSV, etc.
Do you have any comments or thoughts about this post? Please drop us a note at: Contact us
We would love to hear from you!